PRUV開発室
文章校正サービスPRUV、最新の高性能LLM(GPT-5.2、Claude Opus 4.5、Gemini 3 Pro)を選択利用できる「プレミアムAI」サービスを提供開始
カテゴリー:新機能 作成日:2026-02-05文章校正サービスPRUVは、世界最高峰の生成AIモデル(GPT-5.2、Claude Opus 4.5、Gemini 3 Pro Previewなど)を利用して高度な文章校正・推敲ができる新サービス「プレミアムAI」の提供を開始いたしました。
本サービスは、従来のAI校正機能にあった文字数制限や利用回数制限を撤廃し、必要な分だけAIを使用できる「クレジット」をプリペイドで購入できる従量課金制を採用。入力されたテキストデータをサーバに一切保存しないセキュアな設計により、機密性を要するビジネスシーンでも安心してご利用いただけます。
背景
これまでPRUVは、独自のアルゴリズムによる校正に加えて標準的な生成AIによるチェック機能を提供してまいりました。しかし、プロフェッショナルな執筆現場やビジネス文書の作成においては、「より長い文章を一度にチェックしたい」「最新の高性能モデルで精度の高い指摘が欲しい」という要望が高まっていました。
これらに応えるため、ユーザー自身が最適なAIモデルを選択し、制限なく高度な校正を行える「プレミアムAI」を開発いたしました。
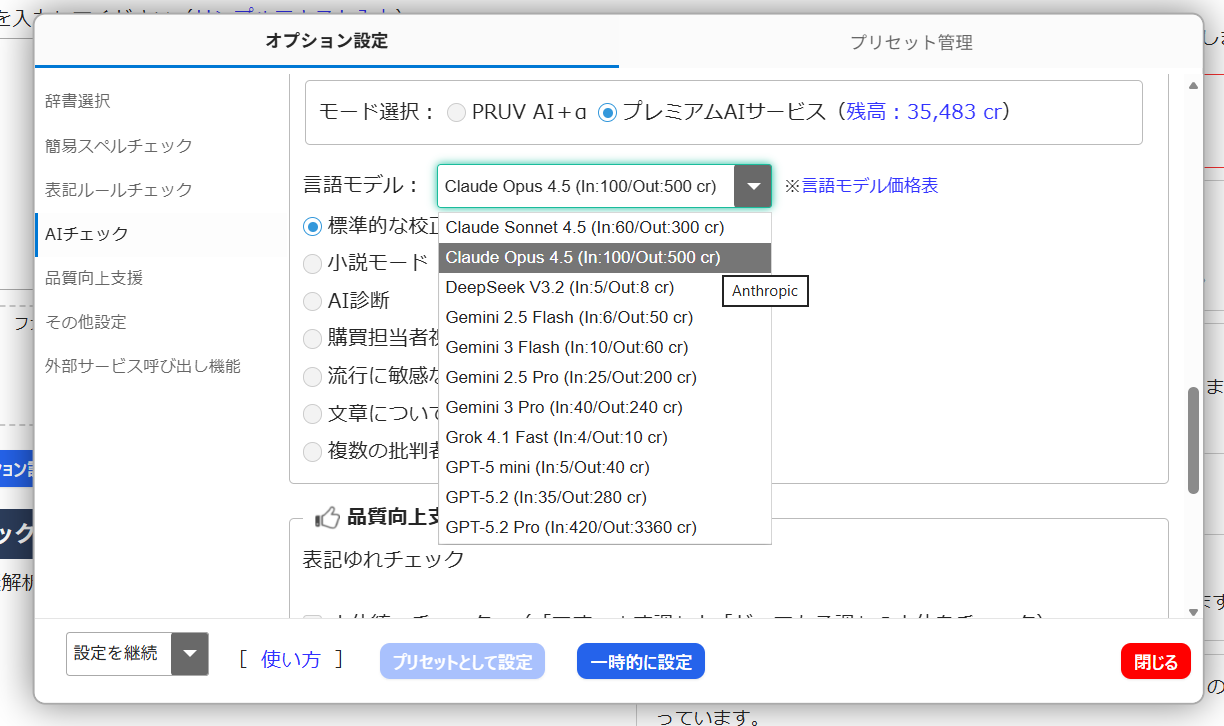
「プレミアムAI」の特徴
1. 世界最高水準のLLMを自由に選択可能
以下の最新モデルから、用途や好みに合わせて自由に切り替えて利用できます。
[続きを読む]
PRUV、自然言語の用語集を解析してAI校正に反映する「カスタムAI」をリリース
カテゴリー:新機能 作成日:2025-12-13PRUVは、ユーザー独自のルールによるAI校正を実現する「カスタムAI」をリリースしました。各種AIを自分専用のAIのようにカスタマイズすることが可能です。
「Aという表記をBにする」という固定的なチェックに強いルールベースチェックと文脈に沿った判断が可能なAI校正の間を補完するもので、「この文脈ではこの表記を使う」「この正しい表記と異なっていたら誤り」といったチェックを実現します。
ルールを適切に作るとAIがそのルールから法則を見つけ出し、定義していないパターンに応用することもあります。AIにルールを教えていくことで、自分専用のAIであるかのように最適化されていきます。
本機能はユーザーID単位で厳密に区別されており、AIに対するルールが他のユーザーに適用されることはありません。ユーザーのルールデータはPRUV AIから独立しており、PRUV AIに取り込むことはありません。
[続きを読む]
PRUV、独自の生成AIによる校正支援機能「PRUV AI」バージョン2をリリース
カテゴリー:新機能 作成日:2025-12-06PRUVは、独自の生成AIを利用した校正支援機能「PRUV AI」をアップデートしました。
PRUV AIはGPTやClaude、Geminiなどの第三者にデータを送信しません。そのため、入力されたテキストはPRUVのポリシーの下で処理されます。テキストを文章の形では一切保存せず、AIの学習にも利用しないことが保証されます。
バージョン2では
・GPUサーバの強化による高速化
・2台のGPUサーバによる負荷分散
・言語モデルの大規模化
・24時間提供
を実現しました。また、旧バージョンでは「AIルーム」として提供していた機能をメイン画面に統合し、各種AI機能を通常の校正フローの中でご利用いただけます。
既存機能、AI機能ともに、今後も最新の技術動向を踏まえながら強化してまいります。ぜひご活用ください。
PRUV AI-Test版の提供とClaude Sonnet 4.5に対応について
カテゴリー:新機能 作成日:2025-11-30PRUVで利用できる外部生成AIを「Claude Sonnet 4」から「Claude Sonnet 4.5」にバージョンアップしました。
また、PRUV独自の生成AIの実験的な実装として「PRUV AI-Test」を公開しました。
PRUV AI-Testは、現行のPRUV AIと一長一短があります。当面は並行して稼働させますが最終的にはどちらか一方のみに一本化する予定です。ぜひ、並行運用中に使い比べてみてください。
どちらも、[校正オプション設定]ボタンを押すと表示されるウィンドウの「AIチェック」で選択できます。
【重要】セキュリティ強化に伴う「二要素認証」必須化について
カテゴリー:お知らせ 作成日:2025-11-22平素よりPRUVに格別のご愛顧を賜り誠にありがとうございます。
昨今の社会情勢におけるサイバーセキュリティリスクの高まりやクレジットカード会社などのコンプライアンス要件厳格化を受け、PRUVではお客様により安全にサービスをご利用いただくため、認証システムの強化を決定いたしました。
つきましては、2026年1月1日から全ユーザー様を対象に「二要素認証(2FA)」を必須化させていただきます。
誠にお手数をお掛けいたしますが、期日までに以下のご対応をお願い申し上げます。
[続きを読む]
PRUV、文章の潜在的なリスクをシミュレーションする機能をリリース
カテゴリー:新機能 作成日:2025-10-19公式発表やプレスリリースなどを前提に、内容に対してどのような批判や反論が想定されるかを複数のAIペルソナ(懐疑的な消費者、競合他社の対象者、法律の専門家)がシミュレーションします。
あえて批判的な視点で文章を評価することで、文章が内包する論理の弱点や炎上リスクをあぶり出します。これらの批判を確認し、論旨や例示を補強するかどうかを検討することで、より堅牢な文章へと進化させることが可能になります。
本機能は、生成AIの活用を模索する実験的な場であるAIルームで提供します。「機能選択」-「文章評価機能」-「複数の批判者が、文章の問題点を指摘」でご利用いただけます。
文章のブラシュアップにぜひご活用ください。
PRUV、ルールベースの校正結果をPRUV AIが補足解説する機能をリリース
カテゴリー:新機能 作成日:2025-10-11ルールベースの校正、つまり辞書やプログラムによって文章を校正する機能の結果をPRUV AIが解析し、補足する機能をリリースしました。
校正を実行すると表示される「基本チェック」タブの各指摘に、【PRUV AIによる補足】というリンクが追加されます。これをクリックするとPRUV AIがさらに詳しく解説します。
山がは見える(PRUVのサンプルテキストより)
に対して、ルールベースの校正機能は
「助詞「が」に助詞「は」が続くのは要確認です。」
と指摘します。
【PRUV AIによる補足】をクリックすると新たなウィンドウが表示され、ここにPRUV AIによる解説が出力されます。
[続きを読む]
PRUV、ユーザー独自のルールによるAI校正機能をリリース
カテゴリー:新機能 作成日:2025-10-06PRUVは、独自のLLM「PRUV AI」を利用して、ユーザー独自のルールでAI校正できる機能をリリースしました。PRUV AIを、あたかも自分専用のAIのようにカスタマイズすることが可能です。
「Aという表記をBにする」という固定的なチェックに強いルールベースチェックと文脈に沿った判断が可能なAI校正の間を補完するもので、「この文脈ではこの表記を使う」「この正しい表記と異なっていたら誤り」といったチェックを実現します。
ルールを適切に作れば、AIがそのルールから法則を見つ出し、定義していないパターンに応用することもあります。AIにルールを教えていくことで、自分専用のAIであるかのように最適化されていきます。
本機能はユーザーID単位で厳密に区別されており、AIに対するルールが他のユーザーに適用されることはありません。そのユーザーが校正を実行するときに、そのユーザーのルールを読み込みます。ユーザーのルールデータはPRUV AIから独立しており、PRUV AIに取り込むことはありません。
ルールは、「間違い」「正しい表記」「理由」の3項目だけで構成されており、Googleスプレッドシートで作成してPRUVに読み込ませるだけです。Googleスプレッドシートのテンプレートをご用意しているので、ワンクリックで作成を開始できます。
PRUVは、校正においてはユーザー独自の校正ルール、表記ルールによる校正を最も重視しており、複雑過ぎるほどの辞書機能を提供しております。今後も、ユーザー独自の表記ルールにマッチした校正環境を提供するために機能の拡充に努めてまいります。
PRUV、AIを活用した簡易アドバイス機能をリリース
カテゴリー:新機能 作成日:2025-10-01PRUVは、独自のLLM「PRUV AI」を利用した簡易アドバイス機能をリリースしました。文章の校正を実行すると、自動的に文章の内容を把握して改善点を提案します。
本機能のポイントは2つあります。
一つは、PRUV本来の機能の処理が終了した後、バックグラウンドで処理することにあります。そのため、AIの推論処理によって校正速度が低下することはありません。簡易アドバイス機能とは無関係に、PRUVによる校正は終了します。この校正結果だけを見て文章の推敲を進めることも可能です。
もう一つは、PRUV内部で処理が完結しているということです。他社の生成AIにデータを送信することはありません。
簡易アドバイス機能よりも詳細な提案が必要な場合は、AIルームの各種機能をご活用ください。
PRUV、AIを活用した機能の専用ページ「AIルーム」を公開
カテゴリー:新機能 作成日:2025-09-28PRUVは、独自のLLM「PRUV AI」を多角的に活用するための専用ページ「AIルーム」を公開しました。画面最上部の「AIルーム」メニューからご利用いただけます。
同ページは、AIを単なる校正機能にとどめない活用方法を模索します。PRUVのメイン機能にも組み込まれている標準的な日本語を前提としたAI校正機能に加え、小説を前提とした校正機能、AIが購買担当者・一般消費者の立場になって製品紹介や製品説明の文章を評価するモード、肯定的な意見を持つ「肯定者」と批判的な意見を持つ「批判者」が文章の要点について議論を交わして問題を浮き彫りにするモード、文章についてAIが助言するAI診断モードなどを実装しています。
これらの機能やモードは、文章のブラッシュアップに最適です。例えば、購買担当者視点で製品紹介記事を評価して納得できない部分や欠けている情報を指摘することで、文章の改善点が明らかになるかもしれません。これまでPRUVではできなかったことが、AIの力を借りることで実現しました。
[続きを読む]