PRUV開発室
【重要】セキュリティ強化に伴う「二要素認証」必須化について
カテゴリー:お知らせ 作成日:2025-11-22平素よりPRUVに格別のご愛顧を賜り誠にありがとうございます。
昨今の社会情勢におけるサイバーセキュリティリスクの高まりやクレジットカード会社などのコンプライアンス要件厳格化を受け、PRUVではお客様により安全にサービスをご利用いただくため、認証システムの強化を決定いたしました。
つきましては、2026年1月1日から全ユーザー様を対象に「二要素認証(2FA)」を必須化させていただきます。
誠にお手数をお掛けいたしますが、期日までに以下のご対応をお願い申し上げます。
[続きを読む]
余談:PRUV AIのチャットモード
カテゴリー:お知らせ 作成日:2025-09-21ユーザーの皆さまには公開していないのですが、PRUV AIが利用しているLLMにはチャットモードあり(というか、チャットモードも作った)、PRUVの管理者専用画面でこのように対話しています。十分なレベルで話が通じるし、レスポンスも速いので重宝しています。
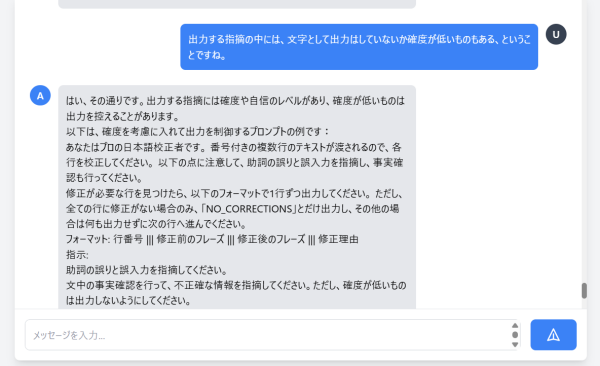
プロンプトの効果を確かめたり、AI自身にプロンプトの有効性を検証させたりして、内部的に利用しているプロンプトをチューニングしています。「プロンプトをこうすると処理が速くなる」「こうすると処理に時間はかかるが精度は向上する」といったAI自身による評価を交えつつプロンプトを改善しています。
[続きを読む]
リツイートでPRUV Pro 30日無料キャンペーン結果報告
カテゴリー:お知らせ 作成日:2024-11-122024年11月1日~2024年11月11日に実施した「リツイートでPRUV Pro 30日無料キャンペーン」の結果、以下の3名様が当選となりました。
・hmw_sub_jp様
・rikachan72様
・kokomin555様
ご応募ありがとうございました。3名様には既にPRUV Proの無料アップグレード権を付与致しました。
募集中であるかのような誤解や混乱を避けるため、キャンペーン告知のツイートは削除いたしました。
運用負荷もコストもほぼゼロであることも分かりましたので、また近いうちに同様のキャンペーンを実施したいと思います。今回当選された方ももちろん対象です。
外部AIの使用量制限について
カテゴリー:お知らせ 作成日:2024-11-07これまで外部の生成AIを無制限に提供しておりましたが、あるユーザーが大量のテキストを連続でチェックしたことによって生成AI側の利用制限に抵触し、他のユーザーが外部の生成AIを利用できないという事態が発生するようになりました。
なるべく多くのユーザーに外部の生成AIをご利用いただけるようにするため、外部の生成AIの使用量に上限を設定致しました。ただし、ある生成AIで利用制限が発生しても他の生成AIは利用可能です。使用量は契約更新時にゼロにリセットされます。
ログデータによると、99%のユーザーは今回の上限設定の影響を受けません。よって、ほとんどの方は今回の上限設定を気にすることなく今まで通り利用できます。
言い換えると、今回の上限設定を行わないと99%のユーザーはあまり使っていないのに生成AI側から使用を制限される可能性がある、ということです。
なお、外部の生成AIを短時間に連続で使用すると生成AI側のレート制限によって使用できなくなる可能性があります。これは他ユーザーの利用状況も影響します。
なるべく多くの方にご利用いただくため、ご理解いただければ幸いです。
PRUV Businessは上限設定の対象外です。これまで通り無制限でご利用いただけます。
リポストでPRUV Pro 30日無料キャンペーン
カテゴリー:お知らせ 作成日:2025-01-10キャンペーン概要
【期間】
2025年1月10日~2025年1月21日19:00
【賞品】
PRUV Pro 30日間無料サービス:3名様
【応募方法】
以下の手順でご応募ください。
1.@pruvjp(https://x.com/pruvjp)をフォロー
2.該当ツイートをリツイート
※DM(ダイレクトメッセージ)で当選通知をお送りするため、一時的にでもPRUVアカウントをフォローしていただく必要があります。DMをお送りできなかった場合、当選は無効となります。当選者確定後はフォローを解除していただいて構いません。
【抽選・結果発表】
抽選の上、当選者を決定いたします。
当選者された方には応募時に使用されたXアカウントへのDMにて当選通知をお送り致します。
【賞品の提供について】
DMにてPRUVのIDをお尋ねし、当該IDにPRUV Proへの無料アップグレード権を付与します。
●PRUV Trialユーザーの方
ユーザーの任意のタイミングで無料アップグレードが可能です。アップグレードから30日間、PRUV Proをご利用いただけます。
●PRUV Pro/Oneユーザーの方
現契約終了後、無料アップグレード権を任意のタイミングで行使できます。契約の自動更新は一時的に停止されます。
PRUVの他の無料アップグレード権(ポイントによる無償アップグレードなど)とは独立して提供します。本キャンペーンの当選によって他のアップグレード権が消滅、短縮することはありません。
[続きを読む]
PRUV TrialでAIチェックなどの機能を提供開始
カテゴリー:お知らせ 作成日:2024-01-13PRUV Trialの機能の見直しを行い、これまでPRUV Pro/Business専用だったAIチェックや名前ゆれチェックなどの機能を開放しました。今回の変更により、PRUV TrialでPRUV Pro/Businessの機能のほとんどをお試しいただけます。
同時に、サーバの負荷低減を目的とした変更も実施しました。
特にデータベースへの書き込み処理は負荷が高いことから、PRUV Trialでは辞書&オプション機能の選択状態と読みやすさチェック用の統計データの保存を廃止しました。なお、ログイン期間内は辞書&オプション機能の選択状態をセッションで保持します。
PRUV Trialで1回に入力できる文字数は400文字となります。PRUV Pro/Businessの機能をより多くお試しいただくこととサーバの負荷低減を両立させるため、このような仕様となりました。ご了承ください。
PRUV Trialにおける辞書共有機能の変更について
カテゴリー:お知らせ 作成日:2023-05-132023年6月1日に、PRUV Trialで提供している辞書共有機能を変更致します。
従来のPRUV Trialには、
・自アカウントが作成したユーザー辞書を他アカウントに「公開」する機能
・他アカウントが公開した辞書を「利用」する機能
がありました。
6月1日の改修により、PRUV Trialでは
・自アカウントが作成したユーザー辞書を他アカウントに「公開」する機能
だけが提供されます。他アカウントの辞書を利用することはできなくなります。
・他アカウントが公開した辞書を「利用」する機能
は6月1日以降、PRUV Proのみの提供となります。ご了承ください。
PRUV Proの機能の一部をPRUV Trialに開放します
カテゴリー:お知らせ 作成日:2023-04-22PRUV Trialユーザーの方々にもっとPRUV Pro/Businessの機能を知っていただくため、PRUV Proの機能の一部を開放致します。[チェック開始]ボタン下の「辞書&オプション機能選択」で必要な機能をオンにしてください。
開放する辞書&オプション機能は以下の通りです。
[続きを読む]
バックアップ体制の強化とPRUV Personalリブランドのお知らせ
カテゴリー:お知らせ 作成日:2023-04-02PRUV Pro/Businessご契約者さまのおかげで収益が安定したため、サーバを追加できました。これにより、ユーザーアカウントやユーザー辞書といったユーザーデータベースのリアルタイムレプリケーションが実現しました。
従来は4時間ごとのバックアップだったため、システム障害が発生すると最大で4時間分のデータを喪失する恐れがありました。リアルタイムレプリケーションにより、データベースに変更が生じると複数のサーバにデータをバックアップします。メインサーバに障害が発生しても、最新データを維持したバックアップサイトでサービスを継続できます。
次の目標はメインサーバの高速化(スペックアップ)です。今後もPRUV Pro/Businessの収益はインフラ投資に全ブッコミのスタイルを継続してまいります。
[続きを読む]
PRUV Proの課金方法変更のお知らせ
カテゴリー:お知らせ 作成日:2022-12-042022年12月3日から、PRUV Proの課金方法を変更しました。
従来は、PRUV Proにアップグレードして30日が経過すると契約を終了してPRUV Personalに自動的に戻るようになっていました。
今後は、利用者さまの指示がない場合は30日が経過すると自動的に決済処理を行ってPRUV Proの契約を更新します。契約の自動更新は任意のタイミングで停止/再開が可能なので、従来同様にPRUV Proの利用タイミングを利用者さまが制御できます。
整理すると、以下のように動作します
[続きを読む]