PRUVの基本操作(文章チェック実行前)
PRUVで文章をチェックするには、テキストエリアにテキストをコピーして[チェック開始]ボタンをクリックするだけです。
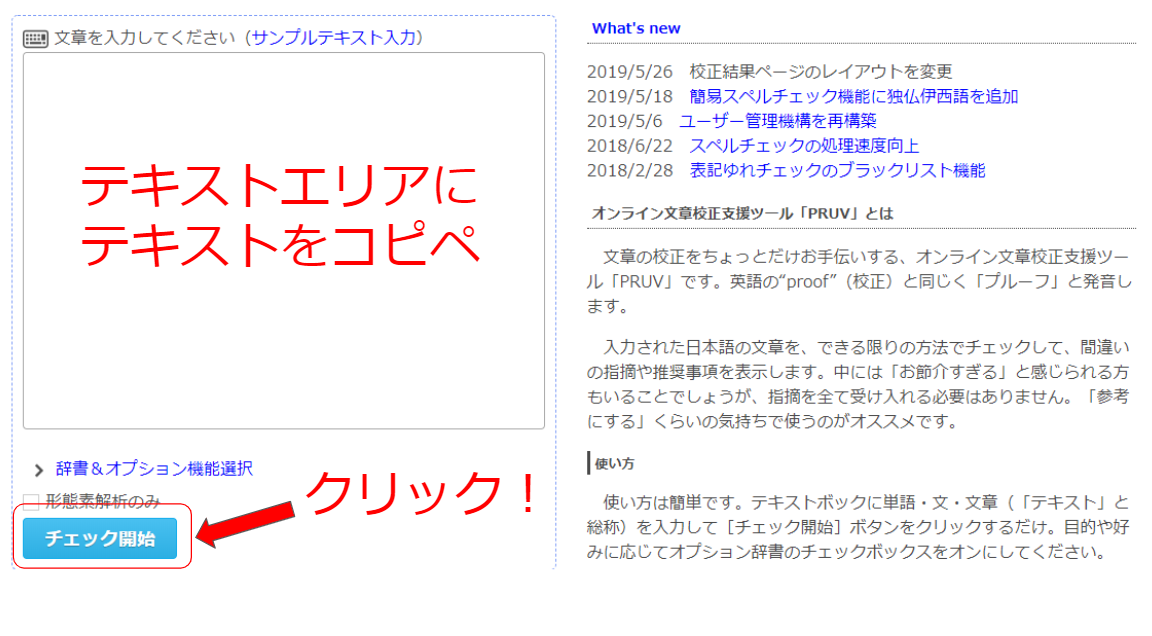
画面1 PRUVの基本画面
設定を変更する場合は、「辞書&オプション機能選択」をクリックします。すると以下のメニューが表示されます(ログインすると表示するように変更されました)。
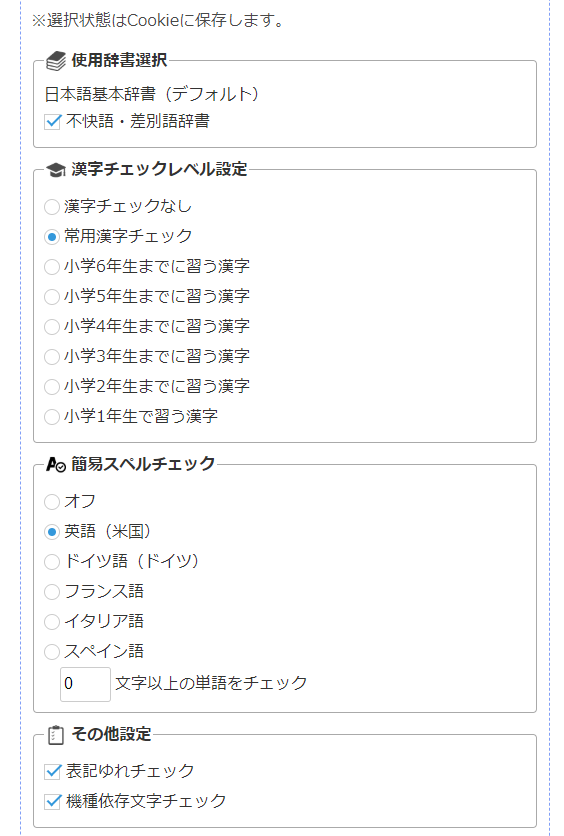
使用辞書選択
漢字チェックレベル設定
デフォルトは「常用漢字チェック」。多くの新聞や雑誌は、常用漢字を基準としつつ独自のルールを加えた表記ルールを定めており、オススメの設定です。
「漢字チェックなし」以外にすると常用漢字表にない音訓(読み方)も検知します。例えば、文章中に「活かす」という表記があった場合、「活」には「い」という読みがないので代わりに「生かす」という表記を提案します。