読みやすさチェック機能
読みやすさチェック機能は、統計情報をベースとしたガイドを提供するものです。
読みやすい文章の基準として「平仮名7割、漢字3割」「読点は0~2個程度」とよくいわれますが、現実問題としてこの比率になることはほとんどありません。文章のテーマや扱う固有名詞によって片仮名やアルファベットも加わり、文字種の比率は大きく変動します。
PRUVの読みやすさチェック機能は、新聞(一般紙)、IT系Webメディア、エンタメ系情報サイト(いずれも複数メディア、サイト)の記事を統計処理してモデルを構築し、このモデルと比較します。
画面1 まず「読みやすさチェックを使う」をオン
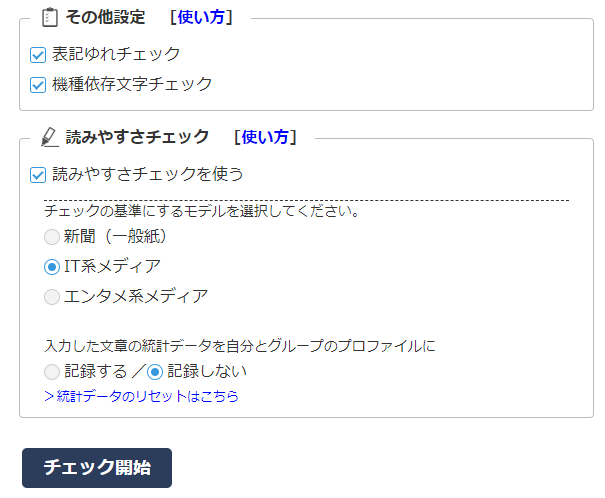
画面2 設定項目が表示される(PRUV Businessの画面)
「読みやすさチェックを使う」をオンにすると、設定項目が表示されます。PRUV Pro/Businessユーザーは、チェックの基準にするモデルを「新聞(一般紙)」「IT系メディア」「エンタメ系メディア」から選択できます。
PRUV Trialユーザーと非ログインユーザーは「新聞(一般紙)」のみ利用可能です。
PRUV Pro/Businessユーザーは自分が入力した文章の統計データを記録し、以降のチェック時に比較対象として表示させることができます。
PRUV Businessはユーザー個人とは別にグループとしてのデータも蓄積します。
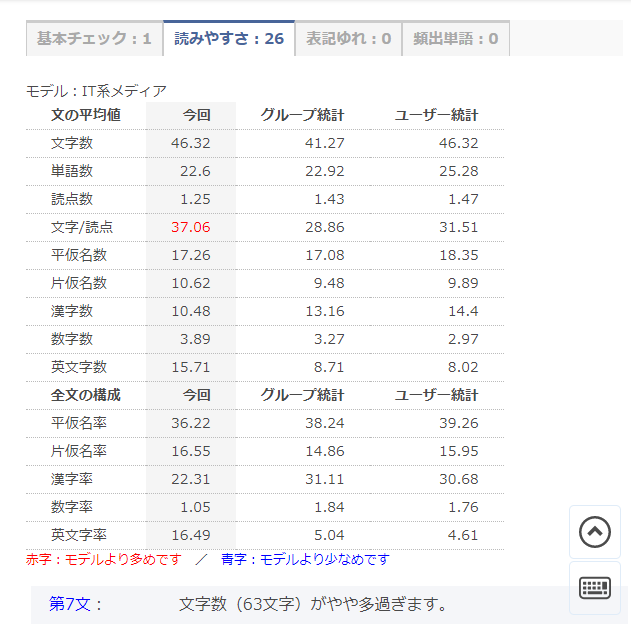
画面3 PRUV Businessでの結果画面
設定後に文章チェックを実行すると、統計情報を出力します。モデルと比較して、多過ぎる要素は赤字、少な過ぎる要素は青字で示されます。さらに、モデルの数値を大幅に上回る文を個別に指摘します。
「文の平均値」は、各文の構成要素を文で割った平均値です。画面3の場合、この文章の文は平均46.32文字であり、文に含まれる読点は平均1.25個……ということになります。
「全文の構成」は、文章の構成比率です。画面3だと漢字は2.2割、平仮名は3.6割。片仮名や英文字(アルファベット)の比率が高いことが分かります。
PRUV Businessは、(記録していれば)グループとユーザーの統計情報が表示されます。データを蓄積していくと各文章の個性が平準化され、グループやユーザーの文章の傾向が見えてきます。
文章全体として見ると、文の文字数が全て平均値付近では単調です。短い文や長めの文があった方がメリハリのある良い文章と言えます。文字数が多過ぎると指摘されたら、念のため読みやすいかどうか読み返してみる程度でよいでしょう。
統計データのリセット
統計データをリセットする場合は、画面2にある「>統計データのリセットはこちら」をクリックします。
ユーザープロファイルの設定画面に移動します。リセットしたいデータをチェックして[リセット]ボタンをクリックしてください。

画面4 リセットデータの選択
PRUV Proユーザーは個人データのみ、PRUV Businessユーザーでグループおよび組織の辞書管理者権限を持っているユーザーはグループデータも選択できます。